,然後再學怎麼從 Table1 轉資料進入 Table2
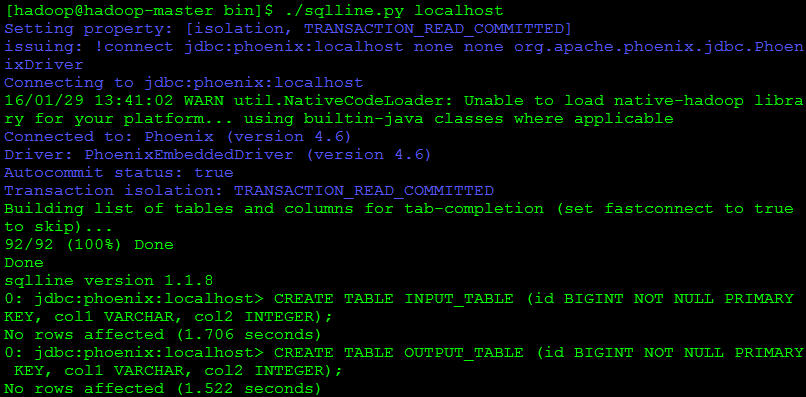
1.首先至 $PHOENIX_HOME/bin 下 執行 sqlline.py localhost(or your zookeeper address)
使用下列 DDL Command Create table
CREATE TABLE INPUT_TABLE (id BIGINT NOT NULL PRIMARY KEY, col1 VARCHAR, col2 INTEGER);
CREATE TABLE OUTPUT_TABLE (id BIGINT NOT NULL PRIMARY KEY, col1 VARCHAR, col2 INTEGER);
2.使用 Spark-shell 準備 insert 資料嘍!
import org.apache.phoenix.spark._
val dataSet = List((4L, "4", 4), (5L, "5", 5), (6L, "6", 6))
sc.parallelize(dataSet).saveToPhoenix("INPUT_TABLE",Seq("ID","COL1","COL2"),zkUrl = Some("192.168.13.61:2181"))

3.回到 Phoneix 查詢結果吧!

Nice ,儲存成功!
------------------------------------------------------------------------------------------------------------------------
現在我們試著寫一段程式將 INPUT_TABLE 資料 存入 OUTPUT_TABLE 吧!
import org.apache.spark.sql._
import org.apache.phoenix.spark._
// Load INPUT_TABLE
val df = sqlContext.load("org.apache.phoenix.spark", Map("table" -> "INPUT_TABLE","zkUrl" -> "localhost"))
// Save to OUTPUT_TABLE
df.save("org.apache.phoenix.spark",SaveMode.Overwrite, Map("table" -> "OUTPUT_TABLE","zkUrl" -> "localhost"))


至此程式執行完畢,緊接著至 Phoenix/bin下使用 sqlline.py 來觀察資料是否寫入成功

資料是否跟剛才 input_table 一樣呢! 如果一樣 那就成功嘍!
沒有留言:
張貼留言