但是如何我要使用 Spark 要如何與 Phoenix 關聯呢?
一般來說會使用 JDBC 但今天我要示範除了JDBC的另外2個方式
此方式是 Phoenix 建議使用的!
在開始前你得先安裝 Spark,參考下面網址將測試資料建置在 Hbase
https://blogs.apache.org/phoenix/entry/spark_integration_in_apache_phoenix
to load data to phoenix hbase be sample data
如果上面網址的範例您可以成功完成,我們可以開始這次的教學了
if you successed to load data and put data to another table EMAIL_ENRON_PAGERANK
you can get count(*) is 36692
-------------------------------------------------
Now I will present to you, spark call phoenix with Apache Spark plugin
with 2 ways to get DataFrame different from jdbc connection.
Please also reference https://phoenix.apache.org/phoenix_spark.html to get RDD.
Now here we go.
First start spark-shell without using driver-class-path
[Remember] When we install phoenix, we have already add driver classpath to environment
請參考上一篇安裝教學
------------------------------------------------------------------------------------------------------------------------
範例一:使用 configuration 取得 DataFrame
$spark-shell
import org.apache.phoenix.spark._
import org.apache.hadoop.conf.Configuration
val configuration = new Configuration()
val df = sqlContext.phoenixTableAsDataFrame("EMAIL_ENRON",Seq("MAIL_FROM","MAIL_TO"),conf = configuration)
df.show(5)
結果如下圖



--------------------------------------------------------------------------------------------------------------------------
範例二:使用Data Source API 取得 DataFrame
import org.apache.phoenix.spark._
val df = sqlContext.load(
"org.apache.phoenix.spark",
Map("table" -> "EMAIL_ENRON", "zkUrl" -> "192.168.13.61:2181")
)
df.show(5)
結果如下圖
(#注意zkUrl是可以變化的,根據你設了幾台zk server for hbase)
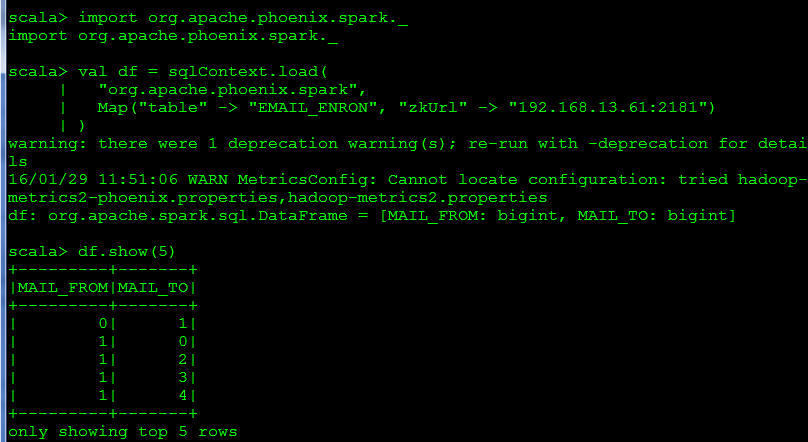
結果與範例一相同呢!
這2種方法,如果程式開發時要一致,通常建議使用Configuration方式,這樣開發人員不用記憶Zookeeper的位置,且能充份發揮Zookeeper的特性,但若是開發時想使用第二種方式也可以,但是請將所有Zookeeper的位置都得加入,像我之前建立5個Zookeeper時,就得如入5個IP address(容錯用)
沒有留言:
張貼留言