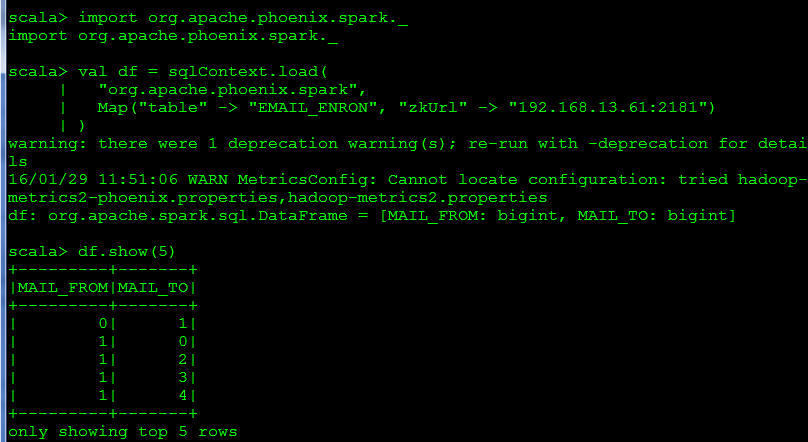
先前學會怎麼用 Spark 取出在Phoenix的資料,現在我們來學學怎麼 save 資料(insert)至 Phoenix
,然後再學怎麼從 Table1 轉資料進入 Table2
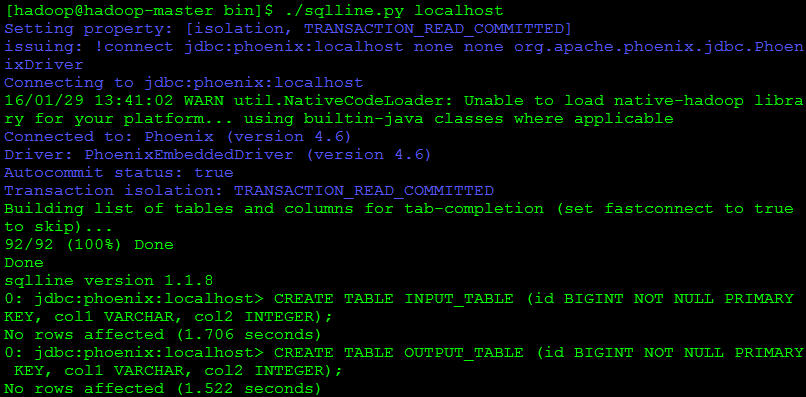
1.首先至 $PHOENIX_HOME/bin 下 執行 sqlline.py localhost(or your zookeeper address)
使用下列 DDL Command Create table
CREATE TABLE INPUT_TABLE (id BIGINT NOT NULL PRIMARY KEY, col1 VARCHAR, col2 INTEGER);
CREATE TABLE OUTPUT_TABLE (id BIGINT NOT NULL PRIMARY KEY, col1 VARCHAR, col2 INTEGER);

2.使用 Spark-shell 準備 insert 資料嘍!
import org.apache.phoenix.spark._
val dataSet = List((4L, "4", 4), (5L, "5", 5), (6L, "6", 6))
sc.parallelize(dataSet).saveToPhoenix("INPUT_TABLE",Seq("ID","COL1","COL2"),zkUrl = Some("192.168.13.61:2181"))

3.回到 Phoneix 查詢結果吧!

Nice ,儲存成功!
------------------------------------------------------------------------------------------------------------------------
現在我們試著寫一段程式將 INPUT_TABLE 資料 存入 OUTPUT_TABLE 吧!
import org.apache.spark.sql._
import org.apache.phoenix.spark._
// Load INPUT_TABLE
val df = sqlContext.load("org.apache.phoenix.spark", Map("table" -> "INPUT_TABLE","zkUrl" -> "localhost"))
// Save to OUTPUT_TABLE
df.save("org.apache.phoenix.spark",SaveMode.Overwrite, Map("table" -> "OUTPUT_TABLE","zkUrl" -> "localhost"))
#注意,我這邊ZK設 localhost,是因為我 Spark-shell 此台Server同時也是 zookeeper 其中之一




至此程式執行完畢,緊接著至 Phoenix/bin下使用 sqlline.py 來觀察資料是否寫入成功

資料是否跟剛才 input_table 一樣呢! 如果一樣 那就成功嘍!
Apache Phoenix is a relational database layer over HBase delivered as a client-embedded JDBC driver targeting low latency queries over HBase data. Apache Phoenix takes your SQL query, compiles it into a series of HBase scans, and orchestrates the running of those scans to produce regular JDBC result sets. The table metadata is stored in an HBase table and versioned, such that snapshot queries over prior versions will automatically use the correct schema. Direct use of the HBase API, along with coprocessors and custom filters, results in performance on the order of milliseconds for small queries, or seconds for tens of millions of rows.
Download From http://www.apache.org/dyn/closer.lua/phoenix/
Be carefully, your must download a match version contrast to HBase
Because my hbase version is 1.1.2, so I download phoenix-4.6.0-HBase-1.1-bin.tar.gz
1. Unzip your phoenix

2.Move them to the place you want

3.Go to Phoenix folder to copy the phoenix-{Phoenix-version}-Hbase-{hbase-version}-server.jar
& phoenix-core-{Phoenix-version}-Hbase-{hbase-version}.jar to $HBASE_HOME/lib
You must do many times for your all hbase(region) servers.

4.Edit environment variables to add classpath for phoenix-client driver
this step is for client to call hbase

 5.After start your hbase and zookeeper, go to $PHOENIX_HOME/bin execute ./sqlline.py localhost (I execute the command on hbase-master, because I install phoenix on it.)
5.After start your hbase and zookeeper, go to $PHOENIX_HOME/bin execute ./sqlline.py localhost (I execute the command on hbase-master, because I install phoenix on it.)

6.Execute 'ctrl + d' to exit phoenix, and now you can try other zookeeper to connect to get zookeeper feature

恭喜成功~*